这个问题源于我对如何确定逻辑模型是否足够好的实际困惑。我有一些模型在成对变量两年后使用成对的个体项目状态。结果成功(1)或不成功(0)。我有在形成双时测量的自变量。我的目的是测试我假设会影响配对成功的变量是否对成功产生影响,并控制其他潜在影响。在模型中,关注变量很重要。
使用中的glm()函数估算模型R。为了评估模型的质量,我做了几件事:默认情况下glm()为您提供residual deviance,AIC和BIC。此外,我已经计算了模型的错误率并绘制了合并残差。
- 完整模型的残差,AIC和BIC小于我估计的其他模型(嵌套在完整模型中),这使我认为该模型比其他模型“更好”。
- 该模型的错误率相当低,恕我直言(如Gelman and Hill,2007,pp.99):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)约为20%。
到目前为止,一切都很好。但是,当我绘制合并的残差(再次遵循Gelman和Hill的建议)时,大部分合并箱位于95%CI之外:
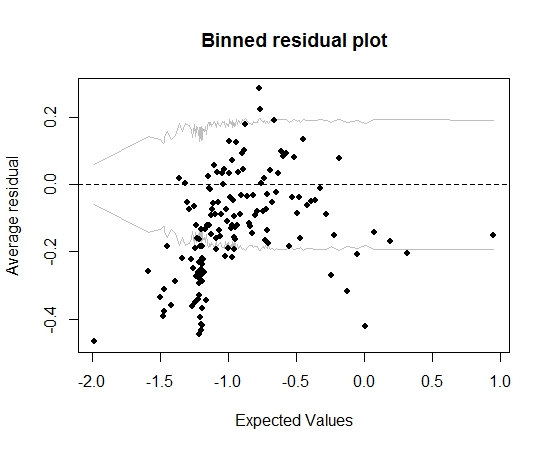
该图使我认为该模型存在某些错误。那应该导致我放弃模型吗?我是否应该承认该模型是不完美的,但可以保留并解释感兴趣变量的影响?我开玩笑地依次排除了变量,并且进行了一些变换,但并没有真正改善合并残差图。
编辑:
- 目前,该模型具有十几个预测变量和5种交互作用。
- 这些对是相对“彼此”独立的,因为它们都是在短时间内形成的(但严格来说不是同时发生的),并且有很多项目(13k)和很多个人(19k) ),因此相当多的项目只能由一个人(大约2万对)加入。
2
做你正在做的事情所需的最低样本量的粗略估计是,你所需要的最低限度的事件数量还是非事件的数量超过15倍(12 + 5),假设你有17点候选人中的术语该模型。如果您使用进行了任何预测变量的筛选,那么所有的选择都将关闭。
—
Frank Harrell
根据您所说的,样本量似乎没有问题,因为我大约有200万对(其中约有20%成功)。
—
Antoine Vernet