在关于文本分类的自动编码器的论文中, Hinton和Salakhutdinov演示了二维LSA(与PCA密切相关)产生的图: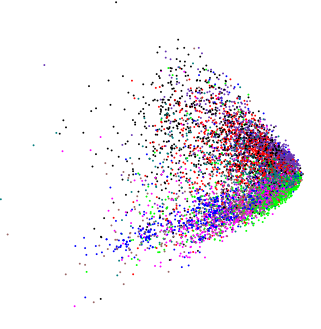 。
。
将PCA应用于绝对不同的略高维度的数据,我得到了一个看起来类似的图:( 在这种情况下,我真的很想知道是否有任何内部结构)。
在这种情况下,我真的很想知道是否有任何内部结构)。
如果我们将随机数据输入到PCA中,则会得到一个圆盘状的斑点,因此这种楔形的形状不是随机的。它本身意味着什么吗?
6
我假设所有变量都是正(或非负)且连续的?如果是这样,则楔形的边缘就是数据将变为0 /负的点。此外,您可以使用正的右偏变量获得与显示的相同模式;观察结果集中在低端。如果您具有正的均匀随机变量,则会看到一个(旋转的)正方形。因此,您显示的模式只是对数据的约束。可以显示其他模式,例如马蹄形,但这不是由于变量范围的限制。
—
加文·辛普森
@GavinSimpson这不仅仅是评论。为什么不将其扩展为答案?
—
Mike Hunter
我问我的孩子(3岁和4岁)这些照片提醒他们什么,他们说这是一条鱼。那么也许是“鱼状”?
—
amoeba
@GavinSimpson,谢谢!在这两种情况下,变量确实都是非负数,在两种情况下,bot都是整数值。这会改变什么吗?
—
macleginn '16







