不幸的是,我们的托管服务提供商经历了100%的数据丢失,因此我丢失了两个托管博客网站的所有内容:
(是的,是的,我绝对应该完成完整的异地备份。不幸的是,我的所有备份都在服务器本身上。因此,请保存演讲;您100%绝对正确,但是此刻对我没有帮助。请继续关注这里的问题!)
我正在开始从Web搜寻器缓存中恢复网站的缓慢而痛苦的过程。
有一些自动工具可以从互联网蜘蛛网(Yahoo,Bing,Google等)的缓存中恢复网站,例如Warrick,但是使用此工具却产生了一些不好的结果:
- 我的IP地址由于使用它而被Google快速禁止
- 我收到很多500和503错误,并且“正在等待5分钟……”
- 最终,我可以更快地手动恢复文本内容
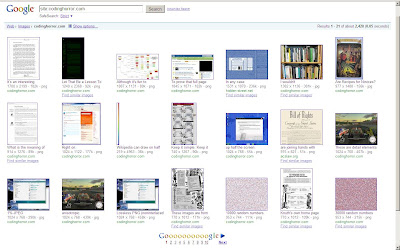
通过使用所有博客文章的列表,单击进入Google缓存并将每个文件另存为HTML,我的运气要好得多。尽管博客文章很多,但博客文章却不多,我认为我应该因缺乏更好的备份策略而自欺欺人。无论如何,重要的是,我很幸运以这种方式获取博客文章文本,而且我绝对能够从Internet缓存中获取网页文本。根据到目前为止的经验,我有信心可以恢复所有丢失的博客文章文本和评论。
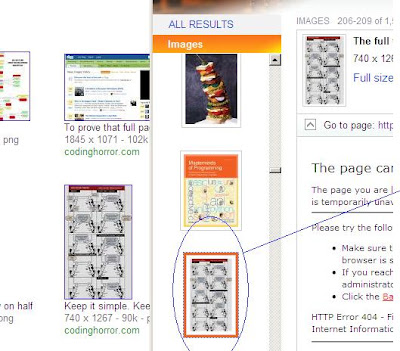
但是,每篇博客文章附带的图片都证明……更加困难。
从Internet缓存恢复网站页面的任何一般技巧,尤其是从网站页面恢复存档图像的地方?
(再次,请不要提供备用讲座。您完全,完全,完全正确!但是正确不能解决我眼前的问题……除非您有时间机器……)
96
当像杰夫·阿特伍德这样的人本可以一口气丢掉两个完整的网站时……恩。我将回顾我自己的备份程序,其中一个:P
joshhunt赢得一(1)个互联网。此优惠不能与其他优惠合并,交换或替代。没有降雨。
—
亚当·戴维斯