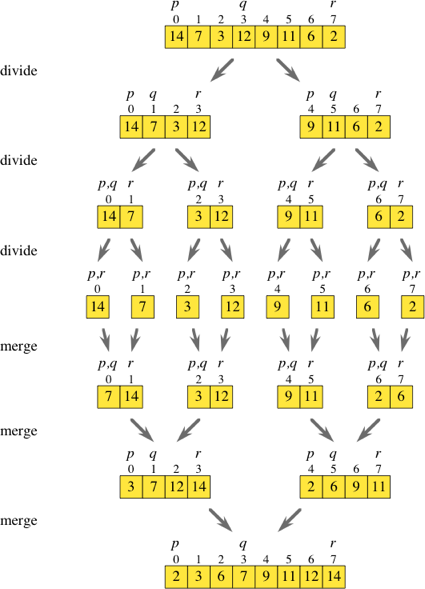
因此,合并排序是一种分而治之的算法。在查看上图时,我在考虑是否有可能基本上绕过所有划分步骤。
如果您在原始数组上跳两次时迭代原始数组,则可以在索引i和i + 1处获取元素,然后将它们放入自己的排序数组中。一旦拥有所有这些子数组(如图所示,[[7,14],[3,12],[9,11]和[2,6]),您就可以简单地进行常规合并例程来获取排序数组。
遍历数组并立即生成所需的子数组是否比整体执行除法步骤效率低?
相关:cs.stackexchange.com/questions/77075/…–
—
奥马尔(Omar),