我刚刚通过sortvis.org博客文章阅读了有关cyclesort的文章。这可能是迄今为止我所听说过的最晦涩的一种语言,因为它使用的是我不熟悉的数学(检测整数集置换中的周期)。
您所知道的最晦涩的是什么?
4
必须回来阅读。
—
Mark C 2010年
很好的时机,我的数据结构类刚刚开始涵盖各种类型。现在,我不仅了解基本种类,而且也了解疯狂的种类。
—
杰森
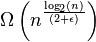 为ε > 0。
为ε > 0。